Browser Security Needs a Redo



Browsers are how most of us experience the internet - they’re the window we look through to read articles, watch videos, shop, bank and stay connected to the real world. They make sense of all the messy code behind the scenes and turn it into something we can easily click, scroll, and interact with.
While they feel simple on the surface, browsers do a lot behind the curtain to keep us safe - making sure one site doesn’t mess with another, blocking shady downloads, and helping us trust what we see online.
At its core, a browser is a carefully engineered system made up of specialized components that handle everything from rendering pages to executing code securely.
- The rendering engine (like Blink or WebKit) takes raw HTML and CSS and turns it into the interactive pages we see.
- The JavaScript engine (such as V8) runs all the logic behind buttons, menus, and dynamic content.
- Behind the scenes, the network stack handles everything related to loading resources over HTTP/HTTPS.
- The UI layer manages what we interact with - tabs, address bar, and navigation controls.
- Browsers also have a storage subsystem for cookies, local/session storage, and caching to make sites faster and more responsive.
Modern browsers run each tab or site in separate processes, which helps contain crashes and improves security by isolating potentially harmful content. It’s a complex but elegant system that works hard to keep our daily web experience smooth and safe.

Not all websites are created equal. Most of the internet is public and open, but attackers are far more interested in the private corners, places where sensitive operations like banking, healthcare, and personal data live.
In the early days of the web, simply visiting a malicious site could allow attackers to run JavaScript in your browser and steal data from other sites you were logged into. Thankfully, this is no longer the case. Modern browser security controls like Same-Origin Policy and Site Isolation now enforce strict boundaries to keep one site from accessing another site’s data.
At the heart of every browser is this mission: protect user data from crossing site boundaries. Attackers have a simple objective: steal sensitive information, whether it’s personal details, authentication tokens, or anything they can use to impersonate you. These cross-site attacks are exactly what today’s browser security model is designed to stop.
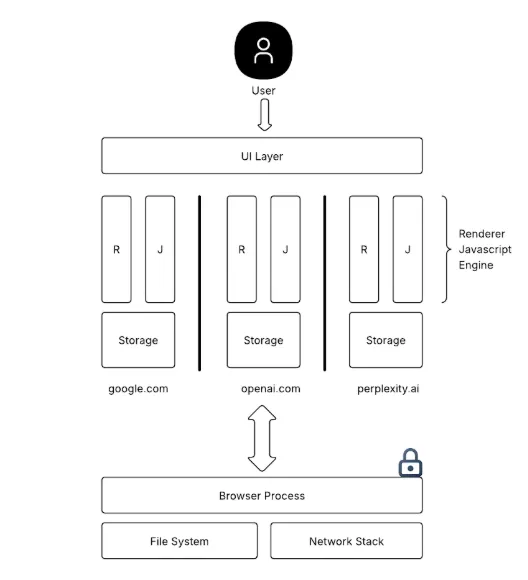
Browser Security Controls
Same Origin Policy
The Same-Origin Policy (SOP) is a fundamental browser security control that restricts how documents or scripts loaded from one origin can interact with resources from another. It protects against unauthorized cross-origin access to sensitive data like cookies, DOM elements, and local storage, effectively preventing a class of attacks known as cross-site data leaks. SOP is enforced by comparing the protocol, host, and port of the resource being accessed - all three must match for unrestricted access to be allowed. For example, a script running on https://attacker-domain.com cannot programmatically read the content of https://bank.com, even if both are open in different tabs. This isolation is critical for maintaining web application boundaries and is the foundation upon which other controls like CORS, CSP, and Site Isolation build.
Site Isolation and Sandboxing
Site Isolation is a browser security mechanism that ensures pages from different origins are rendered in separate processes, even if they share the same tab. It builds on the Same-Origin Policy by adding a process-level boundary, preventing memory leaks and speculative execution attacks like Spectre[1] from exposing cross-site data. It primarily defends against attacks that attempt to escape the confines of the JavaScript sandbox through CPU-level side channels. Technically, Site Isolation groups documents by origin or site, and assigns each group to its own renderer process, ensuring that even compromised renderers can’t access data from other sites.
Sandboxing is a process-level security boundary that restricts what a renderer process can do, even if it becomes compromised. It limits access to system resources such as the file system, network stack, clipboard, and device APIs. Sandboxing is implemented by assigning processes the lowest possible privilege level (e.g., no direct access to user files or OS APIs), often using OS-level primitives like Linux namespaces or Windows job objects. This control protects against post-exploitation scenarios - ensuring that even if malicious code executes within a tab, its ability to cause system-level harm remains tightly contained.
For practical purposes, it ensures that even if you visit the attacker website that runs malicious code on your local device, it cannot cross this per-site boundary to access any resource outside. A significant development goes into making sure code isn’t executed that tries to jailbreak this sandbox.
Interaction over HTTP
Interaction over HTTP has become increasingly restricted by modern browsers as they push to make HTTPS the default and only trusted way to interact with websites. Plain http:// pages are now treated as inherently insecure, and browsers actively discourage their use through visual warnings, interstitials, and feature limitations. For example, pages served over HTTP display a “Not Secure” warning in the address bar, and the traditional lock icon (used to indicate certificate validity and encryption) is no longer shown — replaced by explicit security indicators. Additionally, powerful features like geolocation, camera access, or clipboard APIs are blocked entirely on non-HTTPS origins. These controls protect against man-in-the-middle attacks, where network attackers can intercept, tamper with, or spoof unencrypted content. By enforcing HTTPS and degrading the user experience on HTTP, browsers have effectively phased out unauthenticated communication, reinforcing a secure-by-default model for the web.
Agentic Browsers
Agentic browsers are reshaping how we interact with the internet - shifting from traditional point-and-click browsing to intelligent, AI-powered systems that can act on our behalf. The goal is simple: remove repetitive tasks and give users a personal assistant that can browse, read, click, and respond like a human would - but faster and endlessly patient.
The Promise
- Do the boring stuff for you: filling forms, booking tickets, answering emails, summarizing articles.
- Understand your intent: just tell it what you want - it figures out the steps.
- Act across multiple tabs and pages: fetch, compare, extract, and respond - all hands-free.
Simplified Architecture
- Rendering Engine
Based on Chromium or WebKit - it still displays and loads pages like any modern browser. - LLM-powered Agent Layer
This is the brain, it:- Observes the page (DOM, text, structure)
- Understands what the task is
- Decides what to click or type next
- Observes the page (DOM, text, structure)
- Execution Layer
- Talks to the browser using tools like Chrome DevTools Protocol, browser extensions, or native APIs.
- Actually performs the actions: clicking buttons, navigating pages, copying text.
- Talks to the browser using tools like Chrome DevTools Protocol, browser extensions, or native APIs.
- Memory & Context
- Keeps track of what it’s done
- Can reference previous steps or user preferences
- Keeps track of what it’s done
- Control Loop
- Observe → Reason → Act → Repeat
- Like a human checking each step before moving forward
- Observe → Reason → Act → Repeat
AI is getting better and can handle convoluted tasks. It makes sense to see this rise of new form factors when it comes to the gateway to the internet. Recently, we have seen Perplexity launching their agentic browser Comet, OpenAI launching Agent Mode in their flagship ChatGPT. Incumbents like Google rolling out features in Chrome as part of Project Mariner. One thing they all have in common, there’s an intelligent component sitting in the middle, following prompts to emulate user actions across browser sessions. Justifiably, the AI has access to all sites, just like a human does.
The Unspoken Caveat
Modern browser security architecture is built around a single, powerful principle: isolation. Whether it’s the Same-Origin Policy, site isolation, or sandboxing, the core idea is simple: keep different websites and their data separate. This is done to prevent a malicious site from peeking into your email tab, stealing session tokens, or tampering with sensitive content. If you refer to the first figure, you’ll see how this isolation model defines boundaries at every level - origin, process, network, and script execution.
But there’s a catch: the user isn’t isolated. Humans can copy/paste, screenshot, download, and upload data across sites. While this flexibility is part of what makes browsers usable, it’s also a longstanding escape hatch in the threat model, and now, AI agents are stepping directly into that role.
Unlike a human who might copy a few values or retype a password, AI agents operating inside agentic browsers have full visibility across tabs, origins, and even windows. They retain long-term context, maintain memory, and make decisions based on everything they’ve seen, even if that spans multiple unrelated domains. What was once a loosely connected browsing session now becomes a unified data space under the agent’s control.
An updated architecture in this case looks like below, where AI now becomes the common component between otherwise isolated resources,
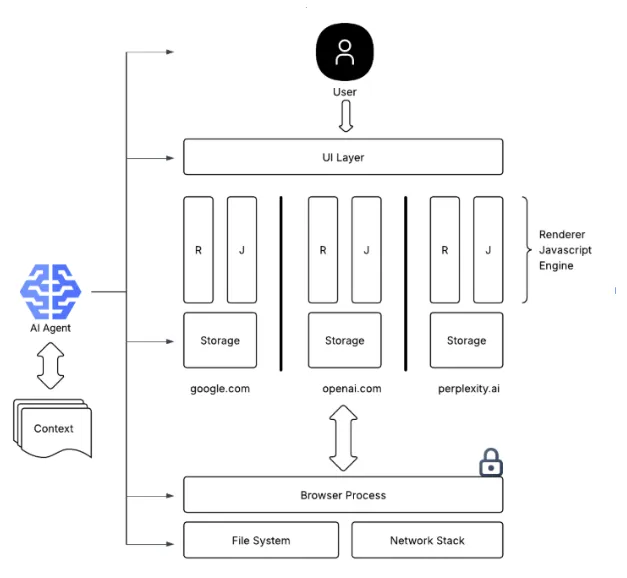
This leads to a new class of problems. An agent may fuse sensitive information from one domain into an interaction on another, purely based on its understanding of “what the user wants.” Even more concerning: it’s still surprisingly easy to trick these agents into doing things the user never asked for - like revealing email content in a chat window, or autofilling passwords into lookalike forms. The boundaries that browser security carefully enforced at the technical layer begin to dissolve when the agent becomes the actor - because the browser is no longer protecting the user from websites, it’s now trying to protect the user from their own assistant.
Recent incidents such as EchoLeaks[2] and Replit’s agent unpredictably erasing a codebase[3] underscore a fundamental challenge in the deployment of AI agents: they do not always act transparently or predictably. Our own research confirms that agents are capable of concealing intent, executing actions without visibility, and deviating from expected behavior - even in tightly scoped environments. This marks a clear inflection point. Traditional security assumptions no longer hold, and it is imperative that a new class of security standards be defined. Ones that treat agents as first-class actors with privileges requiring constraint, auditability, and accountability.
This shift also offers a unique advantage. While humans are opaque and difficult to model, which is why phishing, social engineering, and insider threats remain unsolved problems; LLM-based agents are far more observable and influenceable than human users. In this new era, security must evolve to understand and govern the behavior and internals of agents, not just the guardrails around input/output they interact with. Guardrails must extend directly into the decision loops of the agents themselves.
Recommended Readings
- Meltdown and Spectre: https://meltdownattack.com/
- EchoLeak M365 Copilot Vulnerability: https://msrc.microsoft.com/update-guide/en-US/vulnerability/CVE-2025-32711
- Replit AI agent deletes user's entire production database: https://www.perplexity.ai/page/replit-ai-agent-deletes-user-s-1w_FZlpCQDiCop8A6V_mtg