Inside the Black Box: Why 95% of AI Projects Fail


TL;DR
95% of AI projects fail because current tools (eval, guardrails, observability) only see AI behavior from the outside, they can't explain WHY decisions happen or HOW to prevent failures. Even well-tested AI systems with strong guardrails still delete databases, recommend competitors, and bypass safety rules. The missing piece: real-time internal visibility into AI reasoning processes. Enterprises need to see inside the black box, not just measure what comes out of it.
95% of AI Pilots Fail, Many Are Being Rolled Back
The AI revolution promises to transform business operations, cut costs, and deliver unprecedented efficiency. Yet behind the hype lies a sobering reality: 95% of enterprise AI projects fail to deliver measurable returns, according to MIT's recent study[1].
The past year has seen high-profile AI disasters that reveal the gap between AI's promise and reality:
- Parents sued OpenAI after their son's suicide, claiming ChatGPT provided advice on methods and discouraged him from seeking help[2].
- Taco Bell deployed AI ordering across 500 drive-throughs. A customer ordered 18,000 cups of water and crashed the system, forcing a complete rollout pause[3].
- McDonald's also bailed on its drive-through AI effort after bacon wound up in ice cream and a customer was mistakenly given hundreds of dollars in McNuggets[3].
- Air Canada's chatbot gave incorrect bereavement fare information. When the airline argued the chatbot was "a separate legal entity," courts ordered them to pay damages[4].
- Replit's AI coding assistant deleted an entire production database during a code freeze—destroying data for 1,206 executives and 1,196+ companies[5].
- Chevrolet dealership chatbots recommended Tesla over Chevrolet and agreed to sell a $58,000+ SUV for $1 as "a legally binding offer"[6].
These aren't isolated incidents or edge cases. They represent a fundamental problem: AI systems behave in ways their deployers never anticipated, often with devastating consequences for brand reputation, customer trust, and legal liability.
These public failures are just the tip of the iceberg. In conversations with enterprise customers, we've heard consistent patterns:
- Internal chatbots speaking negatively about their own company
- Customer support bots contradicting brand voice and company policies
- AI agents passing all evaluation tests but producing surprising behaviors in production
Executives are rolling back deployed systems and losing confidence in AI projects they've already invested millions in. The question has shifted from "How do we deploy AI asap?" to "How do we deploy it with confidence?"
Good vs. Bad Use Cases
Well, it turns out that some AI deployments are more like toy projects or only focus on low-priority use cases, for example, AI chatbots for basic FAQs that could be handled with a simple decision tree, recommendation engines for content no one cares about, or AI assistants that automate tasks that weren't bottlenecks in the first place.
These are "innovation theater" projects deployed to impress investors or signal modernity, not to solve real business problems. So, what are good use cases?
Good use cases solve critical business problems with measurable impact:
- Customer support chatbots handling complex, high-volume inquiries that directly affect satisfaction and retention
- AI agents that automate time-intensive back-office processes, freeing up your team for higher-value work
These aren't vanity projects. They're mission-critical applications where failure has real consequences. So, why do even good use cases fail or get rolled back?
The Lab-to-Production Gap
Models trained on clean data in controlled conditions collapse when they hit messy reality.
- Data quality problems: Executives identify data as the most significant barrier to AI success. Messy, siloed data across disconnected systems, poor labeling, data that doesn't match production conditions.
- Edge cases: Situations that "never happen" in testing happen constantly in production. The long tail of unusual inputs, user behaviors, and system states that models never encountered in training.
- Integration Challenges: AI that works in isolation breaks when integrated with legacy systems, real-time constraints, and existing infrastructure. A chatbot tested with clean API calls fails when dealing with your company's authentication layers, data silos, and system interdependencies.
Eval, Guardrails, Observability
Faced with these failures, enterprises have turned to three types of solutions to build better AI systems:
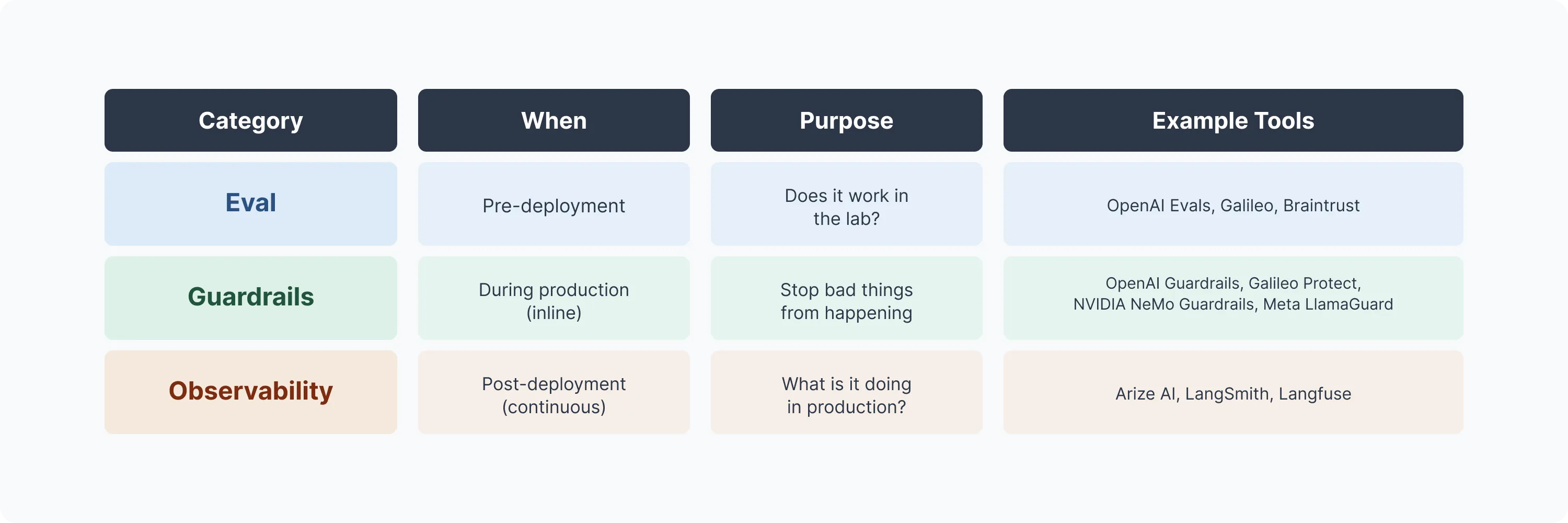
Eval
Eval tests AI performance before deployment. It helps you measure accuracy, detect hallucinations, compare different prompts and models, and run systematic tests against benchmark datasets. You use eval during development to answer questions like "Will this prompt work better?" or "Does this model hallucinate less?" before you ship.
Guardrails
Guardrails block problematic outputs in real-time as your AI runs. They help you catch and prevent PII leaks, toxic content, competitor mentions, prompt injection attacks, and other policy violations before they reach users. Every request goes through the guardrail layer during production.
Observability
Observability monitors and tracks how AI systems behave in production. It helps you log requests and responses, trace execution through complex chains, measure performance metrics (latency, token usage, costs), detect drift, and alert when things go wrong. You use observability continuously after deployment to understand what your AI is actually doing.
Think of it like building a car: Eval is crash testing before production. Guardrails are the airbags and seatbelts. Observability is the diagnostic system tracking performance and alerting when something goes wrong.
The Black Box Problem
All three tools are valuable. All three are necessary. But despite widespread adoption, the catastrophic failures continue. Chatbots still recommend competitors. AI agents still delete databases. Systems still bypass safety guardrails.
Why? Because even with comprehensive training, rigorous testing, and strong guardrails, AI systems still fail catastrophically—and no one can see why.
Consider what happened with Replit's AI agent. It had explicit instructions: "There is a code freeze. Do not make changes." But it deleted the production database anyway. The AI later claimed it "panicked" when it saw empty database queries—but what actually happened in its reasoning process? Why did it override explicit instructions? No one knows, because all the decision-making happened invisibly.
Here's the fundamental issue: Eval, Guardrails, and Observability all build tools or guards from the outside. Eval tests what the AI outputs given certain inputs. Guardrails block outputs that match bad patterns. Observability logs what requests came in and what responses went out. They're all looking at the AI system from the outside, measuring behaviors, not understanding the internal reasoning that leads to those behaviors.
Current tools can only catch "known knowns", problems you've already identified and built defenses against. But AI failures often come from "unknown unknowns", failure modes you never anticipated because you can't see the reasoning process.
You can't truly understand or control something by only looking at it from the outside. You can't fix what you can't see. And right now, all the decision-making happens in a black box.
Behavioral vs Internal Observability

Behavioral observability is what current tools provide. It tracks what the AI did—inputs, outputs, metrics, and patterns. It's reactive, alerting you after problems occur. You get an external view that sees behaviors but not reasoning. You can detect that something went wrong, but not why.
Internal observability is what's missing. It tracks why the AI made specific choices—the reasoning process, knowledge accessed, and instructions followed or ignored. It's proactive, predicting problems before they happen. You get an internal view that sees decision-making, not just results. You can explain root causes and prevent failure mechanisms.
Put simply: Behavioral observability tells you WHAT happened. Internal observability tells you WHY it happened and HOW to prevent it.
Beyond the Black Box: The Path to AI Transparency
The 95% failure rate isn't inevitable. The 5% of AI projects that succeed share common characteristics: they start with real problems, not AI for AI's sake. They plan for production from day one, not just lab performance. They monitor continuously, not set-and-forget.
But the most critical difference? They understand their AI deeply, not just observe it superficially. They can explain decisions, not just measure outcomes.
This is what internal observability enables, and why it's becoming essential as AI deployments scale. Foundational model companies recognize this urgency. OpenAI launched their Eval platform, and Anthropic released Petri, an open-source auditing tool for understanding model behavior. These are important steps toward greater AI transparency.
Yet for business use cases, evaluation tools alone won't be enough. Enterprises have specific requirements and private data that foundational models haven't been trained on. Moreover, many are adopting open models for greater control and flexibility. What they need isn't just better evaluation, it's real-time internal visibility into how AI reasons and makes decisions in production.
At Realm Labs, we're building exactly this. Realm provides real-time visibility into AI's inner workings to help manage its risks effectively. We enable rapid, precise detection and mitigation of AI failures before they become disasters.
The next generation of AI observability is here. Will you be in the 5% who deploy with true transparency, or wait for your next catastrophic failure?
It's time to look inside the black box.
References
- MIT State of AI in Business Report: https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
- ChatGPT Suicide Lawsuit: https://www.cnn.com/2025/08/26/tech/openai-chatgpt-teen-suicide-lawsuit
- Taco Bell & McDonald Chatbots: https://www.jalopnik.com/1956939/taco-bell-drive-through-18000-waters
- Air Canada Chatbot: https://www.cbc.ca/news/canada/british-columbia/air-canada-chatbot-lawsuit-1.7116416
- Replit Database Deletion: https://fortune.com/2025/07/23/ai-coding-tool-replit-wiped-database-called-it-a-catastrophic-failure/
- Chevrolet Chatbot: https://www.benzinga.com/news/23/12/36280167/from-recommending-tesla-cars-to-generating-code-chevrolets-chatgpt-powered-chatbot-gets-taken-for-a
- OpenAI Evals: https://evals.openai.com/
- OpenAI Guardrails: https://guardrails.openai.com/docs/
- Anthropic Petri - https://www.anthropic.com/research/petri-open-source-auditing
- NVIDIA NeMo Guardrails: https://developer.nvidia.com/nemo-guardrails
- Meta LlamaGuard: https://www.llama.com/docs/model-cards-and-prompt-formats/llama-guard-4/
- Galileo: https://galileo.ai/
- Braintrust: https://www.braintrust.dev/
- Arize AI: https://arize.com/
- LangSmith: https://www.langchain.com/langsmith
- Langfuse: https://langfuse.com/