Goodhart’s Law Strikes Again: The Tokenmaxxing Trap

A few months ago, Jensen Huang claimed he'd be "deeply alarmed" if his $500,000 engineer didn't burn through at least $250,000 of tokens.
Enterprises took him at his word. Gripped by AI FOMO, they pushed employees to use AI for everything—even building internal leaderboards to crown whoever consumed the most.
It worked. Within months, engineers were running coding agents, product managers were summarizing calls, and support teams were testing copilots. Dashboards lit up with climbing token counts. The AI transformation looked like a triumph.
Then the bill arrived.
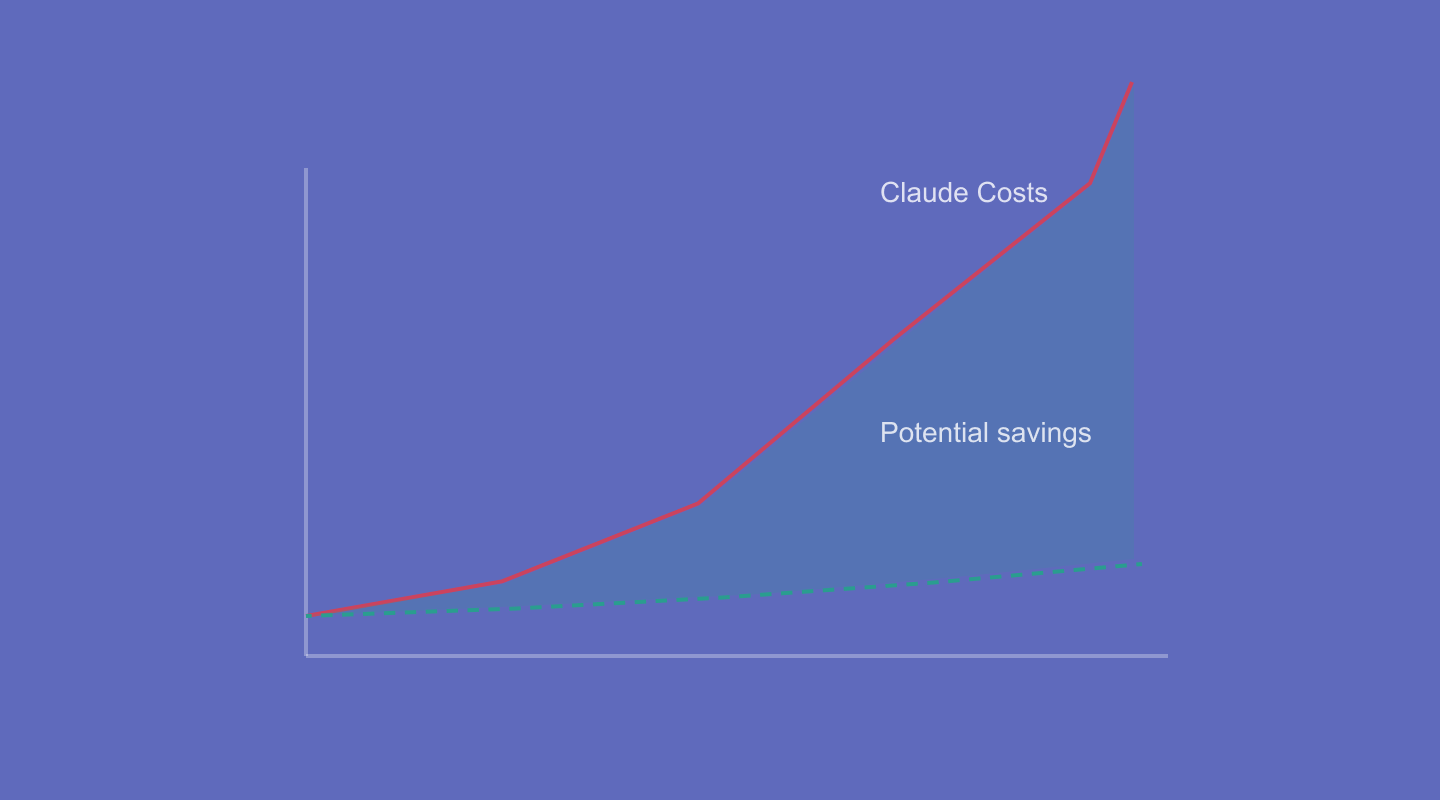
CFOs got sticker shock as usage outpaced every forecast. Uber's CTO said they'd burned their entire annual Claude budget in three months and now limiting each employee to $1500/mo. One company reportedly spent $500M on Claude API costs in a single month.
“Tokenmaxxing” leaderboards quietly disappeared.
What is tokenmaxxing?
Tokenmaxxing is the practice of aggressively maximizing AI usage inside a company, measured in number of tokens.

At first, it sounds rational. If AI is the next productivity platform, then low usage might look like a warning sign. The cost of not using AI is much higher than the cost of using AI.
That is why some companies have created internal leaderboards and informal status games around AI usage. The people burning the most tokens become the visible early adopters. “Tokenmaxxers” look like the employees most committed to the AI transition.
Goodhart’s Law
Goodhart’s Law says: “When a measure becomes a target, it ceases to be a good measure.”
This law appears in every generation of business metrics. When schools target test scores, they teach the test. When call centers target low handle time, agents rush customers off the phone. When software teams target lines of code, developers can produce more code without producing better software.
That is exactly what happens with tokenmaxxing.
As a proxy of AI adoption, it is a useful metric. But once it is treated as a proxy for employee productivity and starts showing up in leaderboards, behavior changes. It incentivises performative AI work over productive AI work.
The hidden costs of AI

AI costs aren't transparent. Five hidden factors drive up the bill (option 1: claude vs option 2: GPT):
- Model capability & effort — Premium models (e.g., Opus 4) cost far more. High "thinking effort" generates extra tokens, even when unnecessary for simple tasks.
- Tokenization tax — Code, markdown, and non-English text tokenize less efficiently. Anthropic's recent Opus tokenizer change produced 25–30% more tokens for the same text—a silent 25–30% price hike.
- Cache economics — Cache writes cost 1.25–2× more upfront. Savings only materialize on cache hits. Low hit rates = wasted spend, yet most teams never track them.
- Model upgrades — New training runs change behavior. Newer models often give longer answers, inflating token usage invisibly.
Tool costs — Managed tools like web search cost ~$0.01/call plus tokens, hidden until the monthly bill.
What should enterprises do?
We are still quite early in the AI adoption curve. Enterprises will draw the wrong lessons if they remove adoption incentives due to high AI budgets alone. What they need to do is to measure what matters.
- What employees are using AI for instead of how much they are using it
- Are the right models and efforts being selected for the right tasks?
- Is AI actually achieving the outcomes the user wanted?
- How many sessions were abandoned due to poor outcomes?
- What is the cache efficacy (writes vs reads)
- Do model or tokenizer changes leading to an increased number of tokens for the same task
The logic is simple: measure the outcomes, not just the usage.
Goodhart’s Law is not a warning against measurement. It is a warning against confusing the measure for the target.
How Realm Labs can help
Observing AI’s intent and semantics is precisely the problem Realm Labs was built to solve. Our Deep Neural Inspection (DNI) can measure the intent of each AI interaction and tell you if it is going toward productivity or wastage. Realm makes AI behavior observable in real time, so you can see what your models are actually doing, catch failures before they reach users, and measure the outcomes that justify the spend.
We are launching a free tool called ClaudeCosts enterprises can use to understand and optimize their Claude bill. Check it out and try it for free at www.claudecosts.com.